Hardening The Shell: Taking AI safety from detection to action
Hardening The Shell: Taking AI safety from detection to action

How we built an end-to-end hallucination detection and correction pipeline that automatically removes 93% of detected hallucinations in clinical notes, increasing hallucination-free notes from 34% to 86% in production
How we built an end-to-end hallucination detection and correction pipeline that automatically removes 93% of detected hallucinations in clinical notes, increasing hallucination-free notes from 34% to 86% in production
How we built an end-to-end hallucination detection and correction pipeline that automatically removes 93% of detected hallucinations in clinical notes, increasing hallucination-free notes from 34% to 86% in production
The Safety Gap in AI Clinical Documentation
AI has transformed clinical documentation, turning 15 minutes of post-consultation typing into seconds. But there's a catch: AI systems hallucinate, confidently stating information that wasn't discussed.
For clinical notes, this isn't just an inconvenience. It's a safety issue.
Consider this: A patient mentions they take paracetamol 'when needed' for headaches. The AI-generated note states 'Patient takes paracetamol 500mg twice daily.' The added specificity seems helpful, but it's fabricated. If another clinician adjusts treatment based on that assumption, they're working with false information.
We've invested heavily in detecting these hallucinations. We first developed a taxonomy of hallucinations and a framework to assess clinical risks, building metrics to identify unsupported content and running our hallucination detection suite across over 500,000 consultations in production.
But detection is only half of the solution. Knowing a note contains hallucinations doesn't make patients safer. Flagging errors for busy clinicians to manually fix adds friction. If we're just generating problems for humans to solve, we haven't fundamentally changed the safety equation.
The real question isn't "can we spot hallucinations?" It's "can we stop them?"
This is the story of how we moved from passive monitoring to active correction. We built a system that automatically removes hallucinations while maintaining note quality and style. It's about closing the loop between evaluation and action, and setting a new standard for AI safety in clinical documentation.
Building The Shell
The challenge was clear: we needed a system that could not only identify hallucinations but correct them automatically, without introducing new errors or degrading the quality of the clinical note.
Our solution centres on a fundamental principle: every correction must be verified before it's applied.
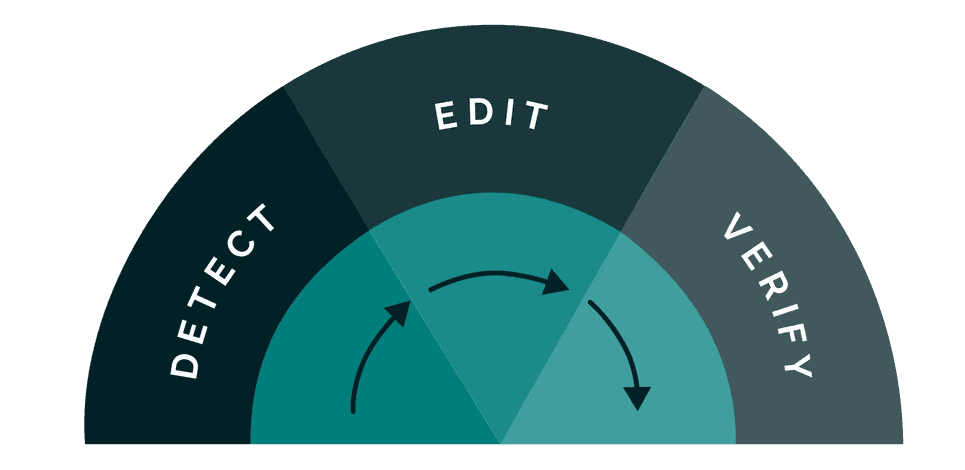
What sets our system apart is a comprehensive suite of verifiers that serve a dual purpose. First, they provide the signals that identify which content in a note is unsupported by the source consultation. But rather than stopping at detection, these same verifiers then ensure that any proposed correction actually solves the problem. This closed-loop approach means we can automatically act on issues with confidence, knowing that every change is validated against the same rigorous standards used to identify the problem in the first place.
When our verifiers identify unsupported content, the system pinpoints the exact span containing the issue, whether that's a single sentence or a short passage. This precision is crucial: it means we can target corrections without touching the rest of the note, preserving the structure, style, and all the accurate content that surrounds the error.
For each identified span, the system determines the appropriate action: removing the content entirely or editing it to align with what was actually discussed in the consultation. Each proposed change is then validated by running it through the same suite of verifiers to confirm it genuinely improves the note and doesn't introduce new issues.
We're not trading one set of problems for another. We're systematically reducing errors while maintaining the clinical accuracy and readability that doctors need.
Balancing Speed and Nuance
%iframe%https://area-yoga-03776696.figma.site/%height=600px;600px;1000px
Once a hallucination is detected, there's a choice: remove it entirely, or attempt to edit it to preserve clinical context while correcting the error. We've designed the system with configurable modes that make different tradeoffs between speed and edit sophistication. Crucially, all modes maintain the same level of safety assurance. The difference lies in how the system handles corrections.
Simple mode takes the fastest, safest approach: identified hallucinations are simply removed from the note. There's no risk of introducing new errors because no new content is generated. The note is guaranteed to be free of unsupported statements, though some clinical context may be lost.
Dynamic mode attempts to preserve more context by editing hallucinations rather than removing them outright. To maintain acceptable latency, this mode only proposes edits for up to a fixed number of detected errors per note. For each correction within this threshold, it proposes an edit that aligns with the actual consultation, then re-verifies that the edit is supported before applying it. This takes longer than simple removal but can produce more complete notes while keeping processing times manageable.
Complete mode goes further, applying the most sophisticated correction strategies to maximise both accuracy and completeness. Every edit undergoes rigorous validation to ensure it genuinely improves the note without introducing new issues.
This flexibility means organisations can choose the right balance for their context. High-volume urgent care settings might prioritise the speed of simple removal, while specialist consultations might benefit from the richer documentation that nuanced edits provide. Either way, the safety guarantee remains the same: no unsupported content makes it into the final note.
But how well does it actually work? To answer that, we needed to test it at scale.
Testing at Scale: Shadow Deployment
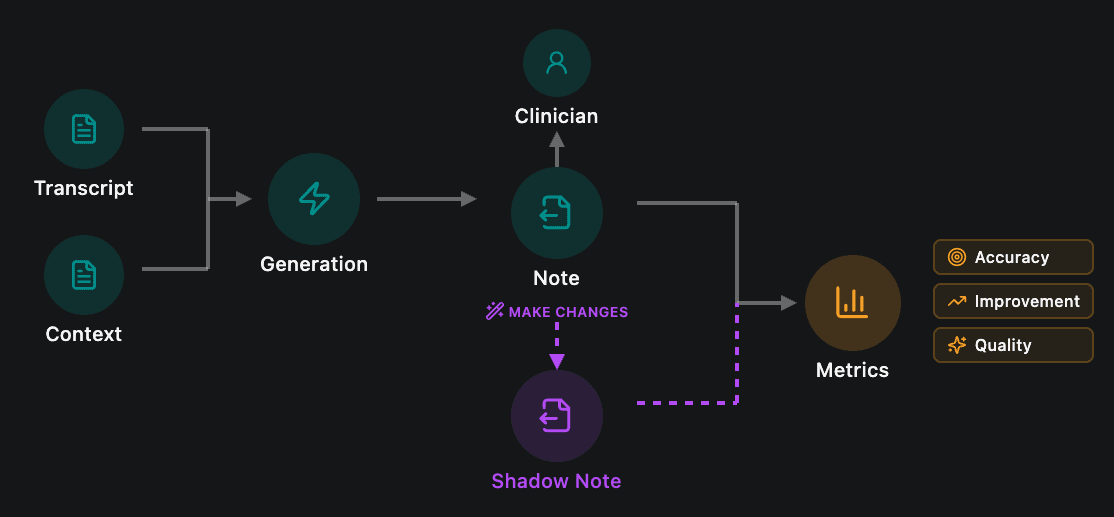
Building confidence in an automated correction system requires more than curated test sets or synthetic data. You need to see how it performs against the full complexity of real clinical practice: the edge cases, the unusual presentations, the varied documentation styles across different specialties and settings.
That's why we ran a shadow deployment across our production environment. From September, we processed over 150,000 consultations where our detection system identified unsupported claims in the generated notes. For each one, The Shell ran in the background, proposing corrections without affecting the notes that clinicians actually received. This allowed us to measure real-world performance at scale while maintaining our strict policy of not storing patient notes or transcripts.
The approach was essential for several reasons. Laboratory testing, no matter how thorough, can't replicate the diversity of real clinical encounters. Production data captures the full spectrum of failure modes: ambiguous consultations, complex multi-problem presentations, regional variations in clinical language, and template-specific quirks. Testing in this environment, while technically challenging given our data retention policies, was the only way to build genuine confidence in the system's safety and effectiveness.
The Results
Of the 150,000+ consultations with identified hallucinations, our pipeline successfully resolved all unsupported claims in 81% of cases. This meant that notes which initially contained fabricated or unsupported content were automatically corrected to contain only information grounded in the actual consultation. Across all 193,410 detected hallucinations, The Shell achieved a 92.7% reduction rate, demonstrating the system's effectiveness across different hallucination categories and establishing a new baseline for clinical documentation accuracy.
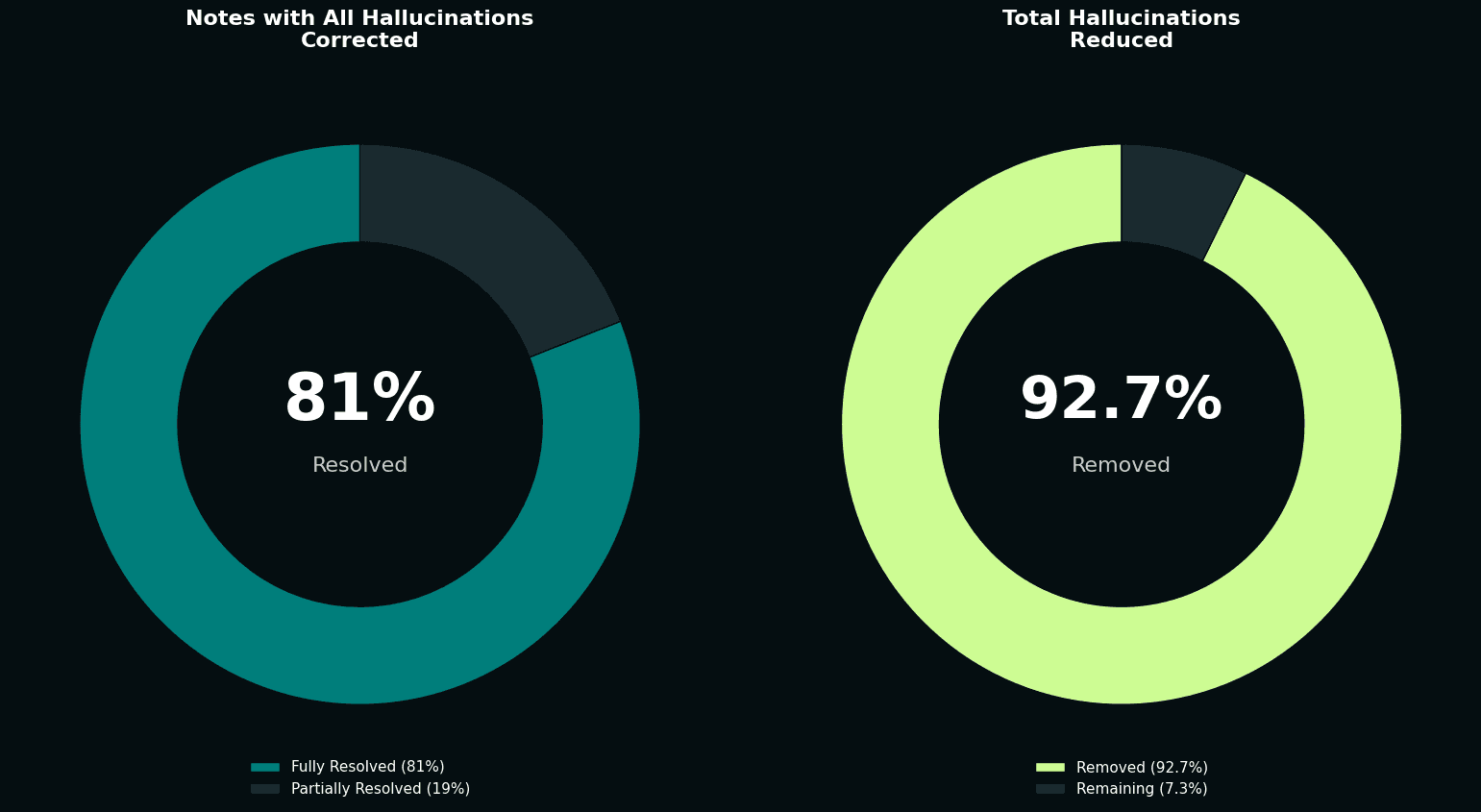
The impact on overall note quality was dramatic. Before correction, roughly a third of notes were completely free of hallucinations. After our automated corrections, that figure rose to over 86%. We more than doubled the proportion of hallucination-free notes, without any manual intervention.
Put another way: we took a population of notes known to contain errors and automatically fixed the vast majority of them, at scale, in real clinical settings.
Competitive Benchmarking
To contextualise these results, we also ran a comparative analysis against other clinical documentation AI systems. Using a controlled set of 50 general practice consultations, we generated notes in the standard SOAP format (Subjective, Objective, Assessment, Plan) across multiple platforms.
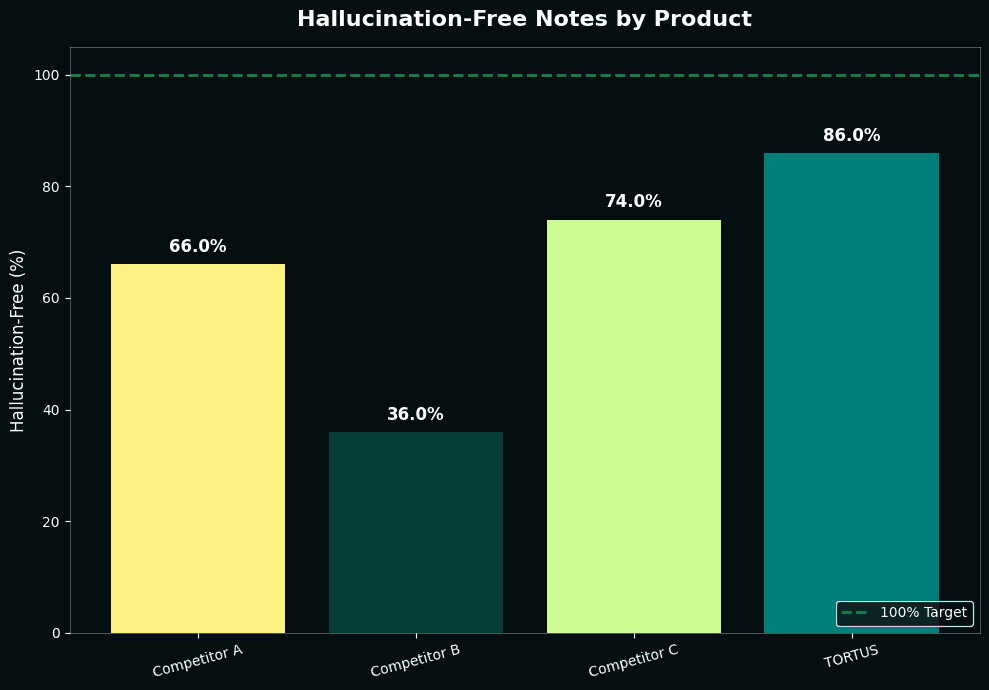
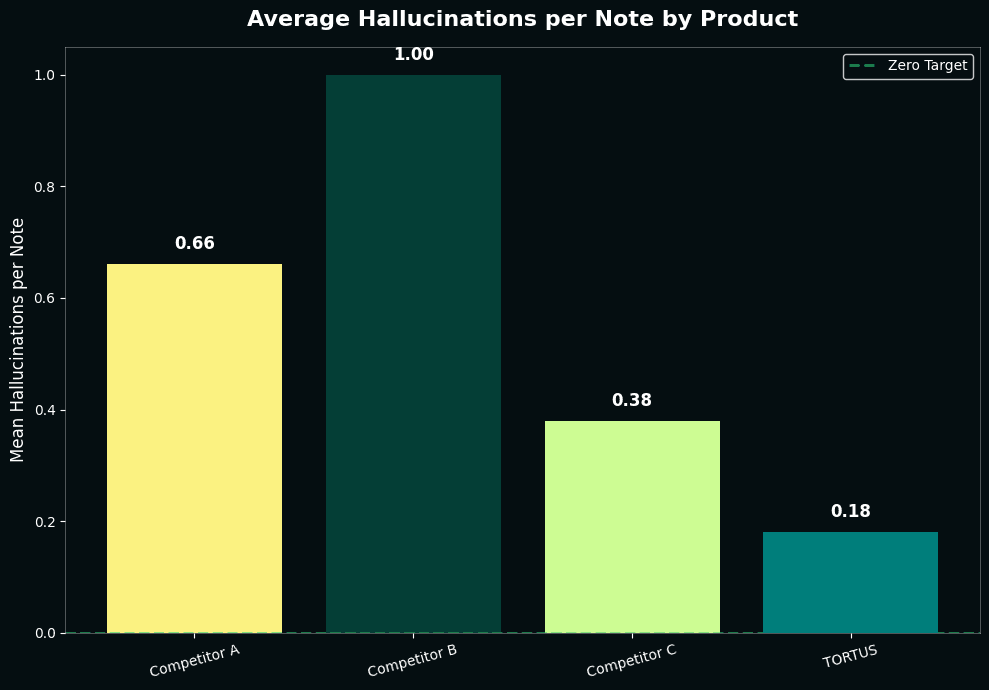
Our system with The Shell achieved 86% hallucination-free notes, replicating what we observed in our shadow deployment. The closest competitor reached 74%. While this appears minor, the underlying difference is significant: our system averages 0.18 hallucinations per note compared to 0.38 for our closest competitor. On a typical production day generating 5,000 notes, this means 1,000 fewer hallucinations were introduced into our notes.
While we're pleased with this lead, the more significant point is the methodology: rigorous, systematic evaluation using consistent detection criteria is the only way to make meaningful comparisons in this space. Without it, claims about safety and accuracy are impossible to verify.
Our Roadmap: Better, Faster, Safer
Reaching 86% hallucination-free notes is significant progress, but it's not the finish line. Our goal is unambiguous: 100% hallucination-free notes that clinicians actually want to use.
That dual aim matters. Safety without usability doesn't help anyone. If notes are technically accurate but clinically awkward, or if the correction process introduces unacceptable delays, we haven't solved the real problem. We need notes that are both safe and valuable to the clinicians who rely on them.
We're continuing to iterate on The Shell in several key areas:
Performance optimisation. Our more sophisticated correction modes currently add latency. We're working to bring those processing times down without sacrificing accuracy, making nuanced edits feasible even in high-volume settings.
Expanding our verifier suite. The current system catches the most common and impactful hallucinations, but there are subtler failure modes we don't yet detect reliably. We're building new verifiers to identify more nuanced errors, things like temporal inconsistencies, contradictions within a note, or missing context that could lead to misinterpretation.
Iterating with clinical feedback. We're building The Shell alongside our existing clinical review systems, including Secure Reports and structured feedback mechanisms. These systems allow clinical teams to review and report on note quality in controlled, privacy-preserving ways. The insights from this human review inform how we refine our approach, prioritising the improvements that will have the greatest impact on clinical safety and note quality.
This is the beginning of a broader shift in how we think about AI safety in healthcare. For too long, the conversation has focused on detection and monitoring, treating errors as inevitable. We believe automated correction, done rigorously and transparently, can change that equation. The Shell is our first step toward making that vision real.
If you're interested in learning more about The Shell or seeing it in action, visit shell.tortus.ai.
The Safety Gap in AI Clinical Documentation
AI has transformed clinical documentation, turning 15 minutes of post-consultation typing into seconds. But there's a catch: AI systems hallucinate, confidently stating information that wasn't discussed.
For clinical notes, this isn't just an inconvenience. It's a safety issue.
Consider this: A patient mentions they take paracetamol 'when needed' for headaches. The AI-generated note states 'Patient takes paracetamol 500mg twice daily.' The added specificity seems helpful, but it's fabricated. If another clinician adjusts treatment based on that assumption, they're working with false information.
We've invested heavily in detecting these hallucinations. We first developed a taxonomy of hallucinations and a framework to assess clinical risks, building metrics to identify unsupported content and running our hallucination detection suite across over 500,000 consultations in production.
But detection is only half of the solution. Knowing a note contains hallucinations doesn't make patients safer. Flagging errors for busy clinicians to manually fix adds friction. If we're just generating problems for humans to solve, we haven't fundamentally changed the safety equation.
The real question isn't "can we spot hallucinations?" It's "can we stop them?"
This is the story of how we moved from passive monitoring to active correction. We built a system that automatically removes hallucinations while maintaining note quality and style. It's about closing the loop between evaluation and action, and setting a new standard for AI safety in clinical documentation.
Building The Shell
The challenge was clear: we needed a system that could not only identify hallucinations but correct them automatically, without introducing new errors or degrading the quality of the clinical note.
Our solution centres on a fundamental principle: every correction must be verified before it's applied.
What sets our system apart is a comprehensive suite of verifiers that serve a dual purpose. First, they provide the signals that identify which content in a note is unsupported by the source consultation. But rather than stopping at detection, these same verifiers then ensure that any proposed correction actually solves the problem. This closed-loop approach means we can automatically act on issues with confidence, knowing that every change is validated against the same rigorous standards used to identify the problem in the first place.
When our verifiers identify unsupported content, the system pinpoints the exact span containing the issue, whether that's a single sentence or a short passage. This precision is crucial: it means we can target corrections without touching the rest of the note, preserving the structure, style, and all the accurate content that surrounds the error.
For each identified span, the system determines the appropriate action: removing the content entirely or editing it to align with what was actually discussed in the consultation. Each proposed change is then validated by running it through the same suite of verifiers to confirm it genuinely improves the note and doesn't introduce new issues.
We're not trading one set of problems for another. We're systematically reducing errors while maintaining the clinical accuracy and readability that doctors need.
Balancing Speed and Nuance
%iframe%https://area-yoga-03776696.figma.site/%height=600px;600px;1000px
Once a hallucination is detected, there's a choice: remove it entirely, or attempt to edit it to preserve clinical context while correcting the error. We've designed the system with configurable modes that make different tradeoffs between speed and edit sophistication. Crucially, all modes maintain the same level of safety assurance. The difference lies in how the system handles corrections.
Simple mode takes the fastest, safest approach: identified hallucinations are simply removed from the note. There's no risk of introducing new errors because no new content is generated. The note is guaranteed to be free of unsupported statements, though some clinical context may be lost.
Dynamic mode attempts to preserve more context by editing hallucinations rather than removing them outright. To maintain acceptable latency, this mode only proposes edits for up to a fixed number of detected errors per note. For each correction within this threshold, it proposes an edit that aligns with the actual consultation, then re-verifies that the edit is supported before applying it. This takes longer than simple removal but can produce more complete notes while keeping processing times manageable.
Complete mode goes further, applying the most sophisticated correction strategies to maximise both accuracy and completeness. Every edit undergoes rigorous validation to ensure it genuinely improves the note without introducing new issues.
This flexibility means organisations can choose the right balance for their context. High-volume urgent care settings might prioritise the speed of simple removal, while specialist consultations might benefit from the richer documentation that nuanced edits provide. Either way, the safety guarantee remains the same: no unsupported content makes it into the final note.
But how well does it actually work? To answer that, we needed to test it at scale.
Testing at Scale: Shadow Deployment
Building confidence in an automated correction system requires more than curated test sets or synthetic data. You need to see how it performs against the full complexity of real clinical practice: the edge cases, the unusual presentations, the varied documentation styles across different specialties and settings.
That's why we ran a shadow deployment across our production environment. From September, we processed over 150,000 consultations where our detection system identified unsupported claims in the generated notes. For each one, The Shell ran in the background, proposing corrections without affecting the notes that clinicians actually received. This allowed us to measure real-world performance at scale while maintaining our strict policy of not storing patient notes or transcripts.
The approach was essential for several reasons. Laboratory testing, no matter how thorough, can't replicate the diversity of real clinical encounters. Production data captures the full spectrum of failure modes: ambiguous consultations, complex multi-problem presentations, regional variations in clinical language, and template-specific quirks. Testing in this environment, while technically challenging given our data retention policies, was the only way to build genuine confidence in the system's safety and effectiveness.
The Results
Of the 150,000+ consultations with identified hallucinations, our pipeline successfully resolved all unsupported claims in 81% of cases. This meant that notes which initially contained fabricated or unsupported content were automatically corrected to contain only information grounded in the actual consultation. Across all 193,410 detected hallucinations, The Shell achieved a 92.7% reduction rate, demonstrating the system's effectiveness across different hallucination categories and establishing a new baseline for clinical documentation accuracy.
The impact on overall note quality was dramatic. Before correction, roughly a third of notes were completely free of hallucinations. After our automated corrections, that figure rose to over 86%. We more than doubled the proportion of hallucination-free notes, without any manual intervention.
Put another way: we took a population of notes known to contain errors and automatically fixed the vast majority of them, at scale, in real clinical settings.
Competitive Benchmarking
To contextualise these results, we also ran a comparative analysis against other clinical documentation AI systems. Using a controlled set of 50 general practice consultations, we generated notes in the standard SOAP format (Subjective, Objective, Assessment, Plan) across multiple platforms.
Our system with The Shell achieved 86% hallucination-free notes, replicating what we observed in our shadow deployment. The closest competitor reached 74%. While this appears minor, the underlying difference is significant: our system averages 0.18 hallucinations per note compared to 0.38 for our closest competitor. On a typical production day generating 5,000 notes, this means 1,000 fewer hallucinations were introduced into our notes.
While we're pleased with this lead, the more significant point is the methodology: rigorous, systematic evaluation using consistent detection criteria is the only way to make meaningful comparisons in this space. Without it, claims about safety and accuracy are impossible to verify.
Our Roadmap: Better, Faster, Safer
Reaching 86% hallucination-free notes is significant progress, but it's not the finish line. Our goal is unambiguous: 100% hallucination-free notes that clinicians actually want to use.
That dual aim matters. Safety without usability doesn't help anyone. If notes are technically accurate but clinically awkward, or if the correction process introduces unacceptable delays, we haven't solved the real problem. We need notes that are both safe and valuable to the clinicians who rely on them.
We're continuing to iterate on The Shell in several key areas:
Performance optimisation. Our more sophisticated correction modes currently add latency. We're working to bring those processing times down without sacrificing accuracy, making nuanced edits feasible even in high-volume settings.
Expanding our verifier suite. The current system catches the most common and impactful hallucinations, but there are subtler failure modes we don't yet detect reliably. We're building new verifiers to identify more nuanced errors, things like temporal inconsistencies, contradictions within a note, or missing context that could lead to misinterpretation.
Iterating with clinical feedback. We're building The Shell alongside our existing clinical review systems, including Secure Reports and structured feedback mechanisms. These systems allow clinical teams to review and report on note quality in controlled, privacy-preserving ways. The insights from this human review inform how we refine our approach, prioritising the improvements that will have the greatest impact on clinical safety and note quality.
This is the beginning of a broader shift in how we think about AI safety in healthcare. For too long, the conversation has focused on detection and monitoring, treating errors as inevitable. We believe automated correction, done rigorously and transparently, can change that equation. The Shell is our first step toward making that vision real.
If you're interested in learning more about The Shell or seeing it in action, visit shell.tortus.ai.
The Safety Gap in AI Clinical Documentation
AI has transformed clinical documentation, turning 15 minutes of post-consultation typing into seconds. But there's a catch: AI systems hallucinate, confidently stating information that wasn't discussed.
For clinical notes, this isn't just an inconvenience. It's a safety issue.
Consider this: A patient mentions they take paracetamol 'when needed' for headaches. The AI-generated note states 'Patient takes paracetamol 500mg twice daily.' The added specificity seems helpful, but it's fabricated. If another clinician adjusts treatment based on that assumption, they're working with false information.
We've invested heavily in detecting these hallucinations. We first developed a taxonomy of hallucinations and a framework to assess clinical risks, building metrics to identify unsupported content and running our hallucination detection suite across over 500,000 consultations in production.
But detection is only half of the solution. Knowing a note contains hallucinations doesn't make patients safer. Flagging errors for busy clinicians to manually fix adds friction. If we're just generating problems for humans to solve, we haven't fundamentally changed the safety equation.
The real question isn't "can we spot hallucinations?" It's "can we stop them?"
This is the story of how we moved from passive monitoring to active correction. We built a system that automatically removes hallucinations while maintaining note quality and style. It's about closing the loop between evaluation and action, and setting a new standard for AI safety in clinical documentation.
Building The Shell
The challenge was clear: we needed a system that could not only identify hallucinations but correct them automatically, without introducing new errors or degrading the quality of the clinical note.
Our solution centres on a fundamental principle: every correction must be verified before it's applied.
What sets our system apart is a comprehensive suite of verifiers that serve a dual purpose. First, they provide the signals that identify which content in a note is unsupported by the source consultation. But rather than stopping at detection, these same verifiers then ensure that any proposed correction actually solves the problem. This closed-loop approach means we can automatically act on issues with confidence, knowing that every change is validated against the same rigorous standards used to identify the problem in the first place.
When our verifiers identify unsupported content, the system pinpoints the exact span containing the issue, whether that's a single sentence or a short passage. This precision is crucial: it means we can target corrections without touching the rest of the note, preserving the structure, style, and all the accurate content that surrounds the error.
For each identified span, the system determines the appropriate action: removing the content entirely or editing it to align with what was actually discussed in the consultation. Each proposed change is then validated by running it through the same suite of verifiers to confirm it genuinely improves the note and doesn't introduce new issues.
We're not trading one set of problems for another. We're systematically reducing errors while maintaining the clinical accuracy and readability that doctors need.
Balancing Speed and Nuance
%iframe%https://area-yoga-03776696.figma.site/%height=600px;600px;1000px
Once a hallucination is detected, there's a choice: remove it entirely, or attempt to edit it to preserve clinical context while correcting the error. We've designed the system with configurable modes that make different tradeoffs between speed and edit sophistication. Crucially, all modes maintain the same level of safety assurance. The difference lies in how the system handles corrections.
Simple mode takes the fastest, safest approach: identified hallucinations are simply removed from the note. There's no risk of introducing new errors because no new content is generated. The note is guaranteed to be free of unsupported statements, though some clinical context may be lost.
Dynamic mode attempts to preserve more context by editing hallucinations rather than removing them outright. To maintain acceptable latency, this mode only proposes edits for up to a fixed number of detected errors per note. For each correction within this threshold, it proposes an edit that aligns with the actual consultation, then re-verifies that the edit is supported before applying it. This takes longer than simple removal but can produce more complete notes while keeping processing times manageable.
Complete mode goes further, applying the most sophisticated correction strategies to maximise both accuracy and completeness. Every edit undergoes rigorous validation to ensure it genuinely improves the note without introducing new issues.
This flexibility means organisations can choose the right balance for their context. High-volume urgent care settings might prioritise the speed of simple removal, while specialist consultations might benefit from the richer documentation that nuanced edits provide. Either way, the safety guarantee remains the same: no unsupported content makes it into the final note.
But how well does it actually work? To answer that, we needed to test it at scale.
Testing at Scale: Shadow Deployment
Building confidence in an automated correction system requires more than curated test sets or synthetic data. You need to see how it performs against the full complexity of real clinical practice: the edge cases, the unusual presentations, the varied documentation styles across different specialties and settings.
That's why we ran a shadow deployment across our production environment. From September, we processed over 150,000 consultations where our detection system identified unsupported claims in the generated notes. For each one, The Shell ran in the background, proposing corrections without affecting the notes that clinicians actually received. This allowed us to measure real-world performance at scale while maintaining our strict policy of not storing patient notes or transcripts.
The approach was essential for several reasons. Laboratory testing, no matter how thorough, can't replicate the diversity of real clinical encounters. Production data captures the full spectrum of failure modes: ambiguous consultations, complex multi-problem presentations, regional variations in clinical language, and template-specific quirks. Testing in this environment, while technically challenging given our data retention policies, was the only way to build genuine confidence in the system's safety and effectiveness.
The Results
Of the 150,000+ consultations with identified hallucinations, our pipeline successfully resolved all unsupported claims in 81% of cases. This meant that notes which initially contained fabricated or unsupported content were automatically corrected to contain only information grounded in the actual consultation. Across all 193,410 detected hallucinations, The Shell achieved a 92.7% reduction rate, demonstrating the system's effectiveness across different hallucination categories and establishing a new baseline for clinical documentation accuracy.
The impact on overall note quality was dramatic. Before correction, roughly a third of notes were completely free of hallucinations. After our automated corrections, that figure rose to over 86%. We more than doubled the proportion of hallucination-free notes, without any manual intervention.
Put another way: we took a population of notes known to contain errors and automatically fixed the vast majority of them, at scale, in real clinical settings.
Competitive Benchmarking
To contextualise these results, we also ran a comparative analysis against other clinical documentation AI systems. Using a controlled set of 50 general practice consultations, we generated notes in the standard SOAP format (Subjective, Objective, Assessment, Plan) across multiple platforms.
Our system with The Shell achieved 86% hallucination-free notes, replicating what we observed in our shadow deployment. The closest competitor reached 74%. While this appears minor, the underlying difference is significant: our system averages 0.18 hallucinations per note compared to 0.38 for our closest competitor. On a typical production day generating 5,000 notes, this means 1,000 fewer hallucinations were introduced into our notes.
While we're pleased with this lead, the more significant point is the methodology: rigorous, systematic evaluation using consistent detection criteria is the only way to make meaningful comparisons in this space. Without it, claims about safety and accuracy are impossible to verify.
Our Roadmap: Better, Faster, Safer
Reaching 86% hallucination-free notes is significant progress, but it's not the finish line. Our goal is unambiguous: 100% hallucination-free notes that clinicians actually want to use.
That dual aim matters. Safety without usability doesn't help anyone. If notes are technically accurate but clinically awkward, or if the correction process introduces unacceptable delays, we haven't solved the real problem. We need notes that are both safe and valuable to the clinicians who rely on them.
We're continuing to iterate on The Shell in several key areas:
Performance optimisation. Our more sophisticated correction modes currently add latency. We're working to bring those processing times down without sacrificing accuracy, making nuanced edits feasible even in high-volume settings.
Expanding our verifier suite. The current system catches the most common and impactful hallucinations, but there are subtler failure modes we don't yet detect reliably. We're building new verifiers to identify more nuanced errors, things like temporal inconsistencies, contradictions within a note, or missing context that could lead to misinterpretation.
Iterating with clinical feedback. We're building The Shell alongside our existing clinical review systems, including Secure Reports and structured feedback mechanisms. These systems allow clinical teams to review and report on note quality in controlled, privacy-preserving ways. The insights from this human review inform how we refine our approach, prioritising the improvements that will have the greatest impact on clinical safety and note quality.
This is the beginning of a broader shift in how we think about AI safety in healthcare. For too long, the conversation has focused on detection and monitoring, treating errors as inevitable. We believe automated correction, done rigorously and transparently, can change that equation. The Shell is our first step toward making that vision real.
If you're interested in learning more about The Shell or seeing it in action, visit shell.tortus.ai.